
概述
本节教程讲述ComfyUI中的通义万象方案来实现用图片替换视频中的人物生成一个新的视频,建议基于此文章=>ComfyUI的下载与AI绘图使用 | 一篇文章即可学会搭建好ComfyUI后,再看本文。
效果预览

使用步骤
步骤1:导入工作流
工作流见概述中提到的文章链接中的网盘链接中的通义万象视频人物替换。
下载后,按照如下图,将工作流“修改版video_wan2_2_14B_animate.json”放入到路径“ComfyUI_windows_portable\ComfyUI\user\default\workflows”中
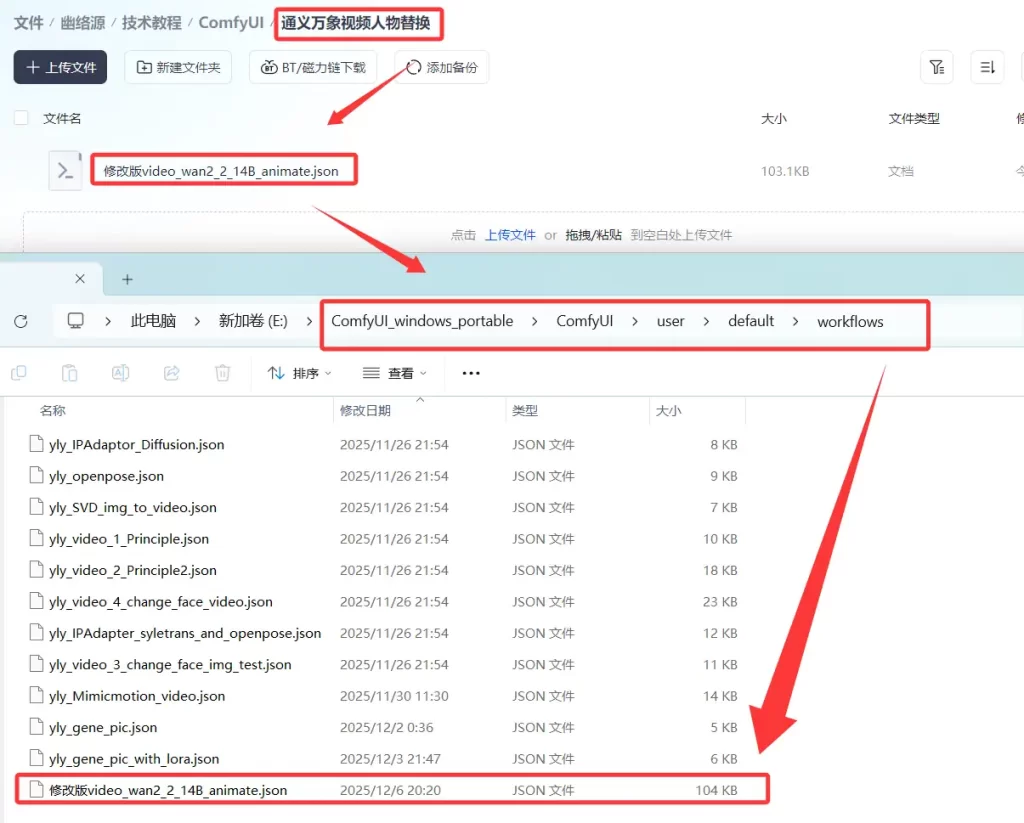
步骤2:下载相关模型
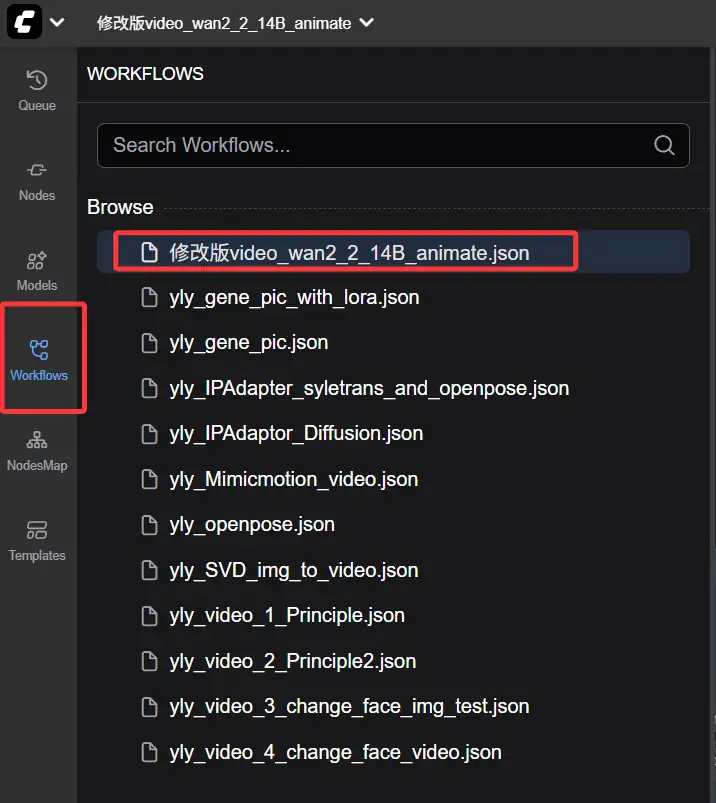
启动ComfyUI,在WorkFlows中选择下载的工作流,如图
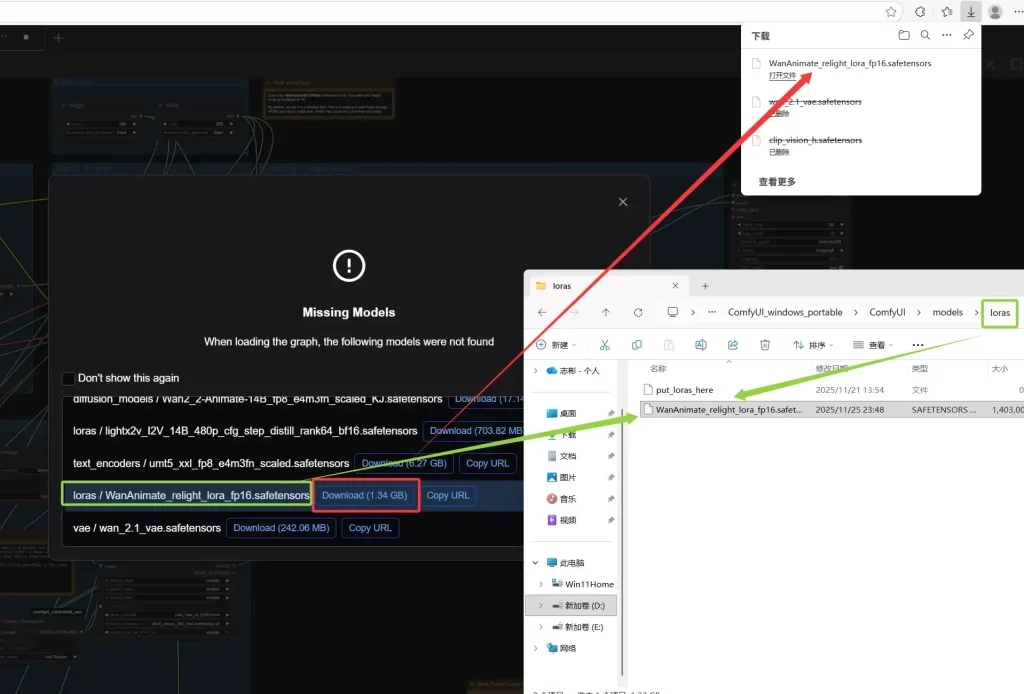
第一次导入此类工作流并且若无相关模型会弹出一个Missing Models提示框,会显示我们缺失的相关模型,我们只需安装提示框所说的点击Download按钮下载模型然后放置到提示的目录下即可,如图
步骤3:配置工作流
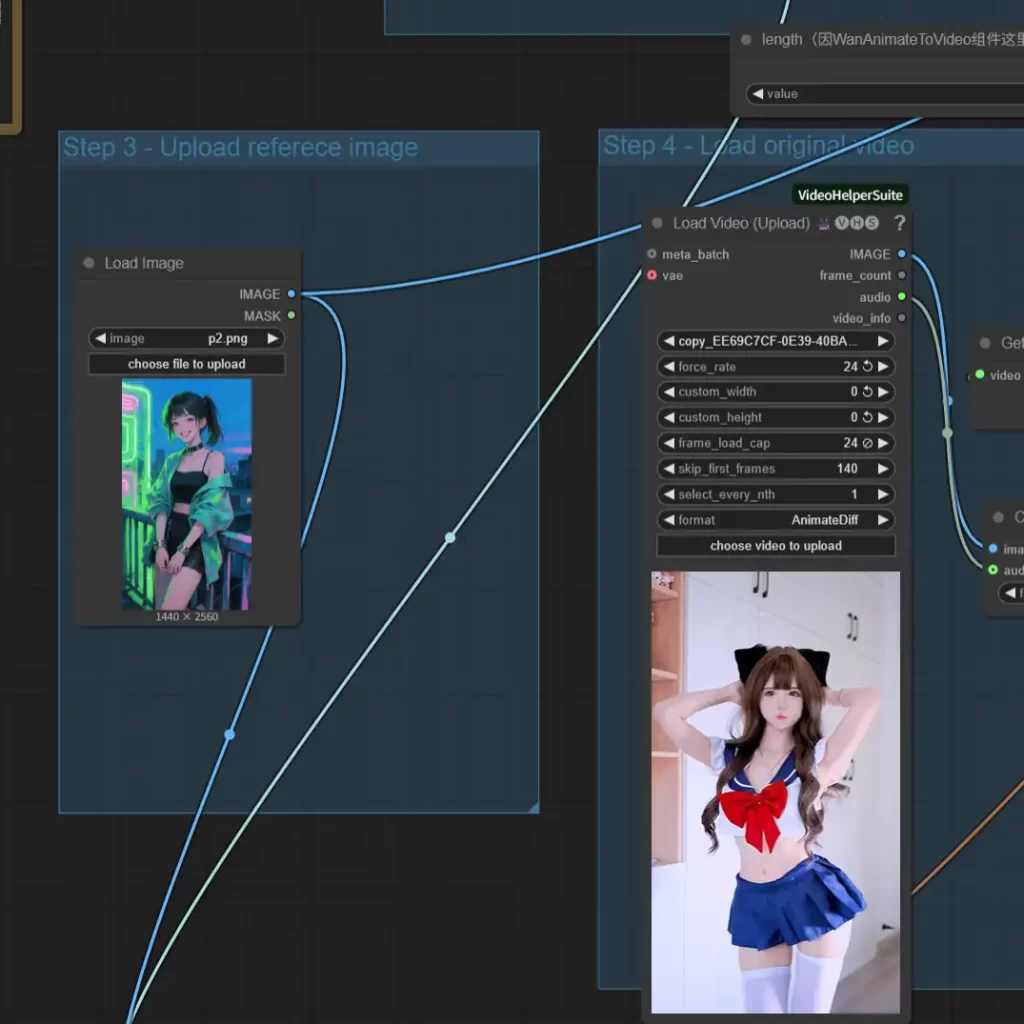
3.1 上传图片和视频
如下图,step1块不用管,都是加载模型,然后step3为上传一张图片,step4中有一个上传视频的节点,将需要替换人物的视频和期望视频中出现的人物分别上传到节点即可
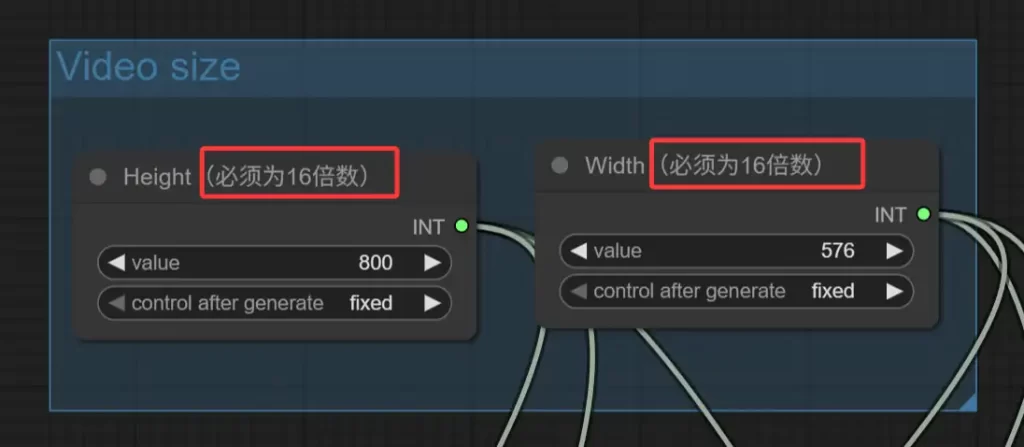
3.2 配置期望导出视频的宽高
在step2节点上方有一个Video size组,如下图,Height为期望导出视频的高度,Width为期望导出视频的宽度,这两个节点幽络源已经添加上了提示,也就是非常重要的这里的像素配置必须为16的倍数,否则必定生成失败。
3.3 配置视频帧数相关信息
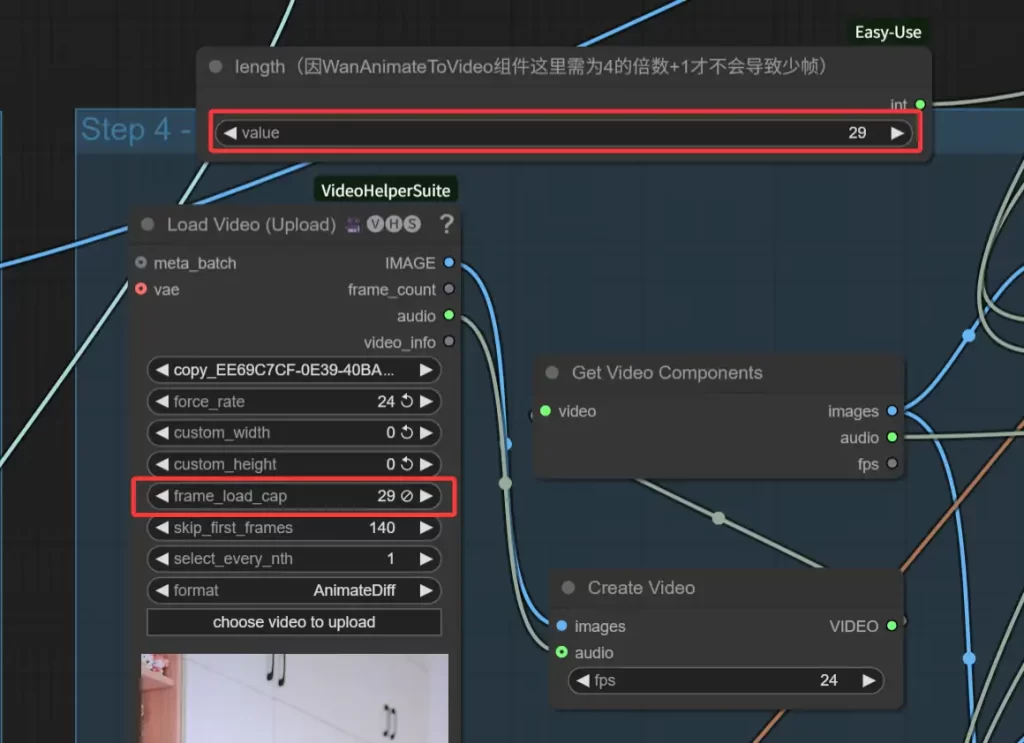
如下图,这里的LoadVideo节点是我们上传的视频,但我们不一定说是要全部视频导出,因此
通过LoadVideo节点的skip_first_frames属性可以控制跳过的帧数
通过LoadVideo节点的frame_load_cap属性可以控制需要的总帧数
通过LoadVideo节点的force_rate属性可以控制视频的每秒帧数
然后这里幽络源要特别提及的是总帧数的问题,下图的length节点幽络源这里是连接到了WanAnimateToVideo节点的,而WanAnimateToVideo节点是强制视频帧数为4的倍数+1,因此幽络源这里建议这里的length要调整为4的倍数+1,然后保持LoadVideo的frame_load_cap和这里的length一致
3.4 预览图打点标记
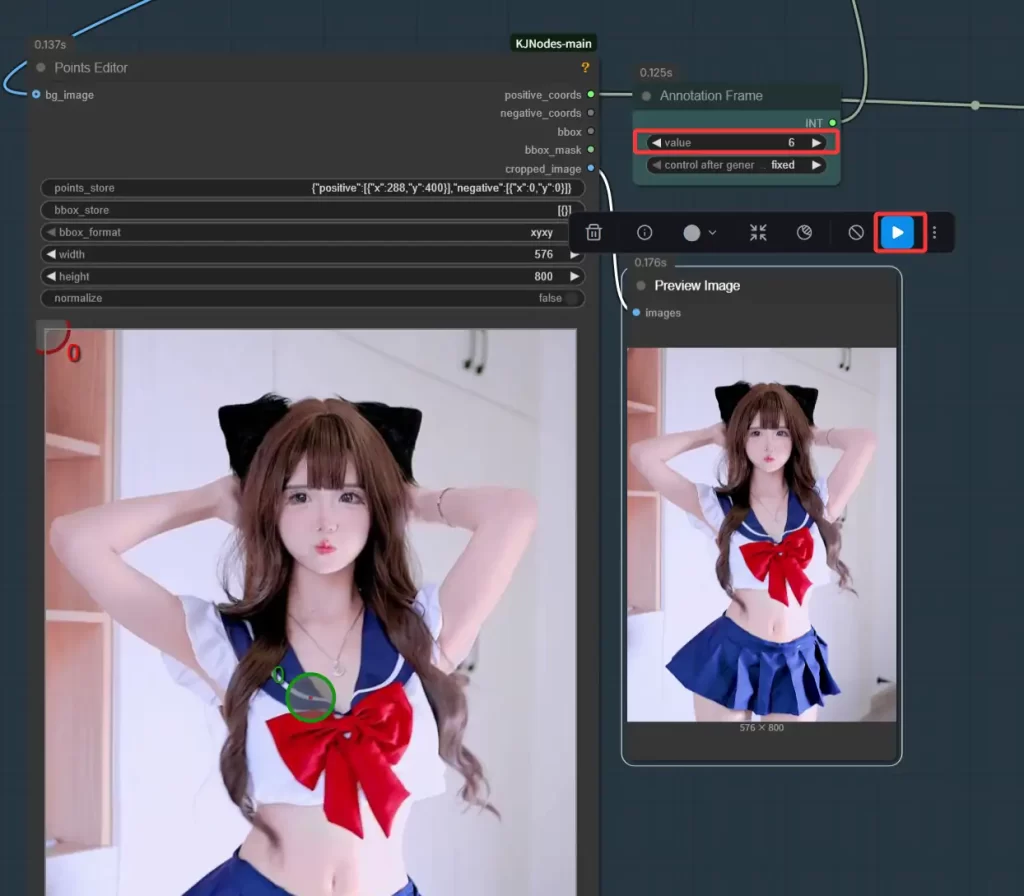
预览图打点标记主要是辅助工作流区分人物和背景。
如下图,调整AnnotatationFrame节点的value值可以指定选择我们上传的视频中的某一帧,然后点击PreviewImage节点的执行按钮,即可将选择的那帧加载到Points Eidtor节点中,这一帧我们最好是选择能完整加载人物的头、身体、手等各个部位。
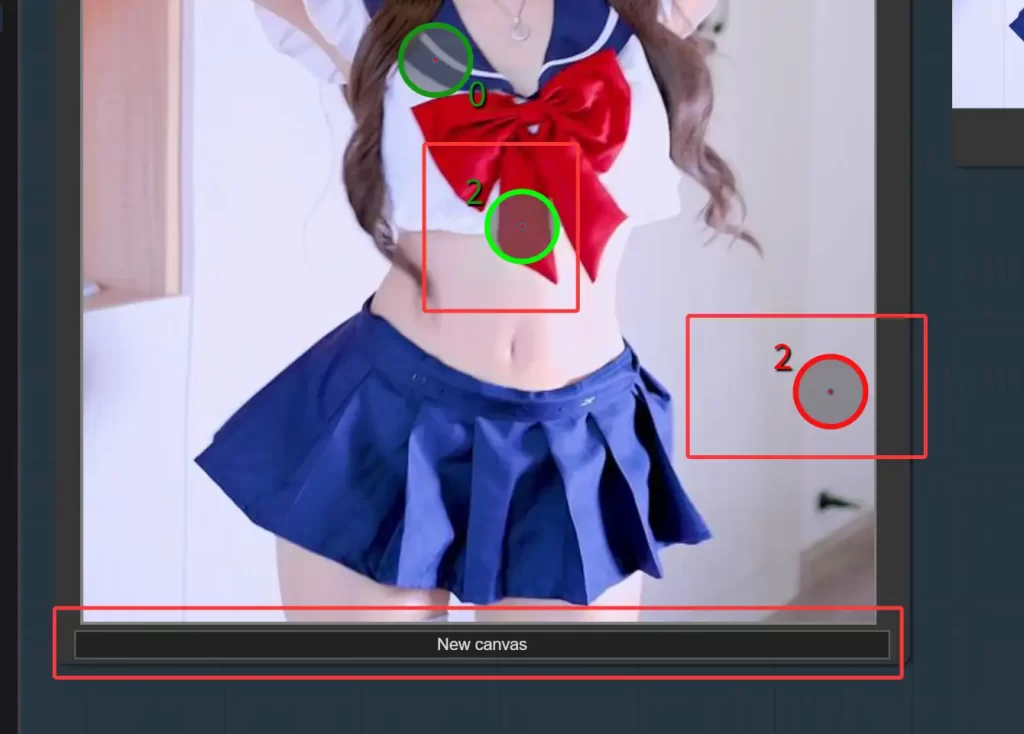
然后是打点,如下图
按住shift+鼠标左键打上绿色的点来定位我们期望替换的地方->也就是人物
按住shift+鼠标右键打上红色的点来定位我们期望不需要替换的地方->也就是背景
然后下方的New Canvas按钮则可以清除所有的点
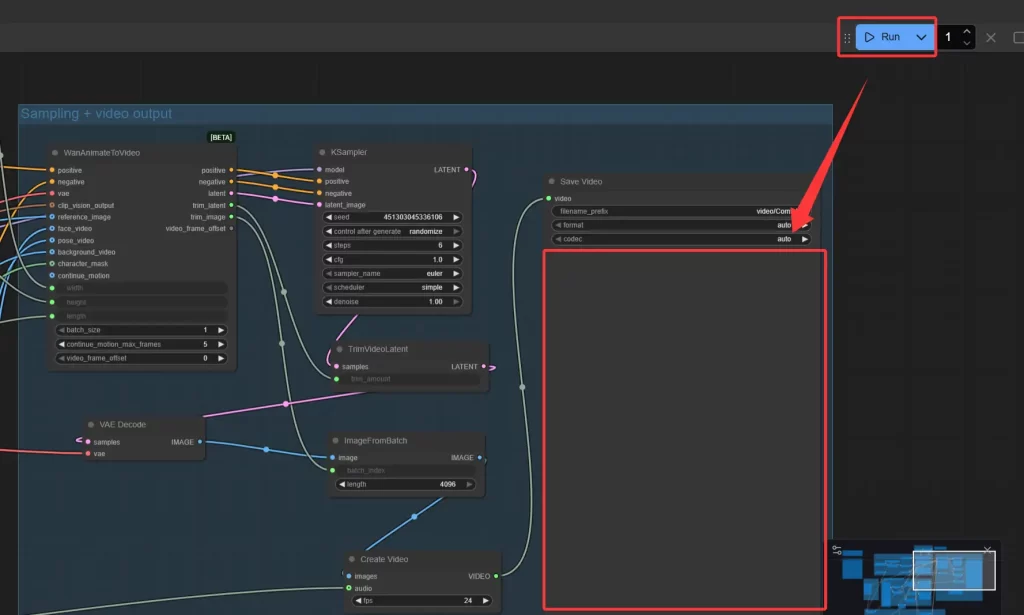
3.5 执行工作流
配置完成后,点击执行工作流,最终即可在最后的节点save video中得到我们生成的视频,如图
效果预览
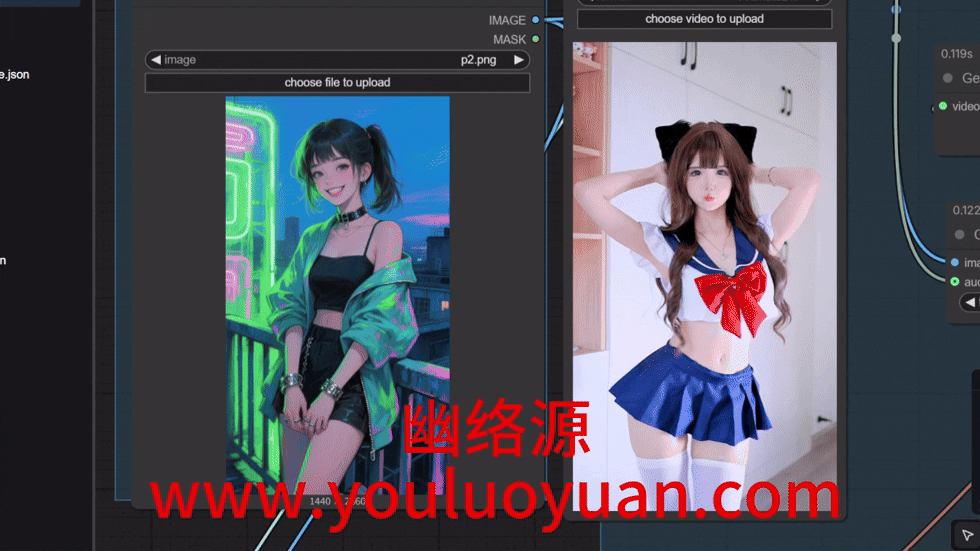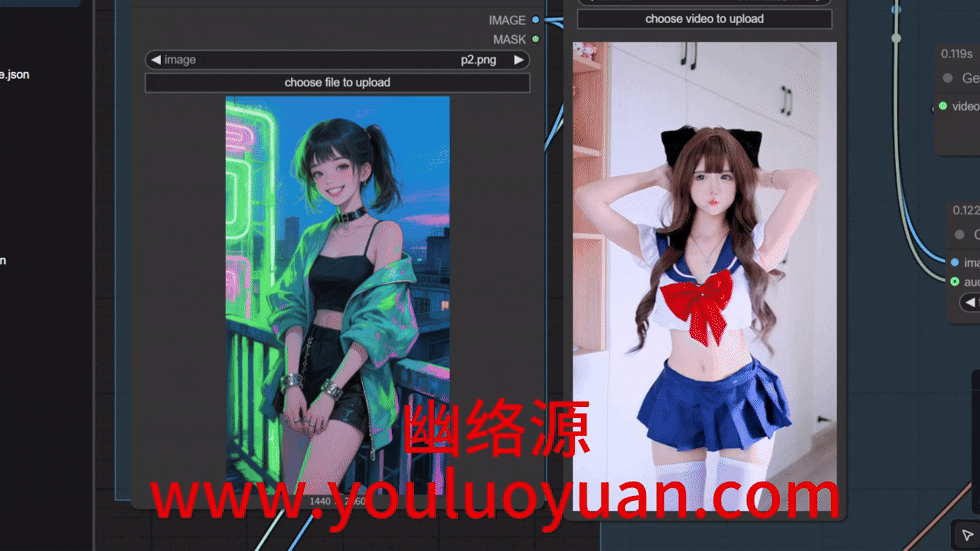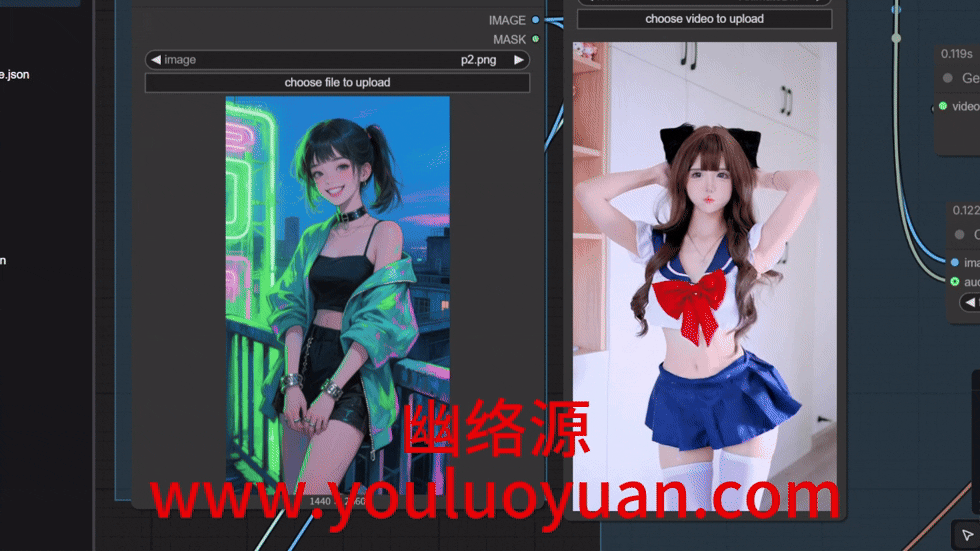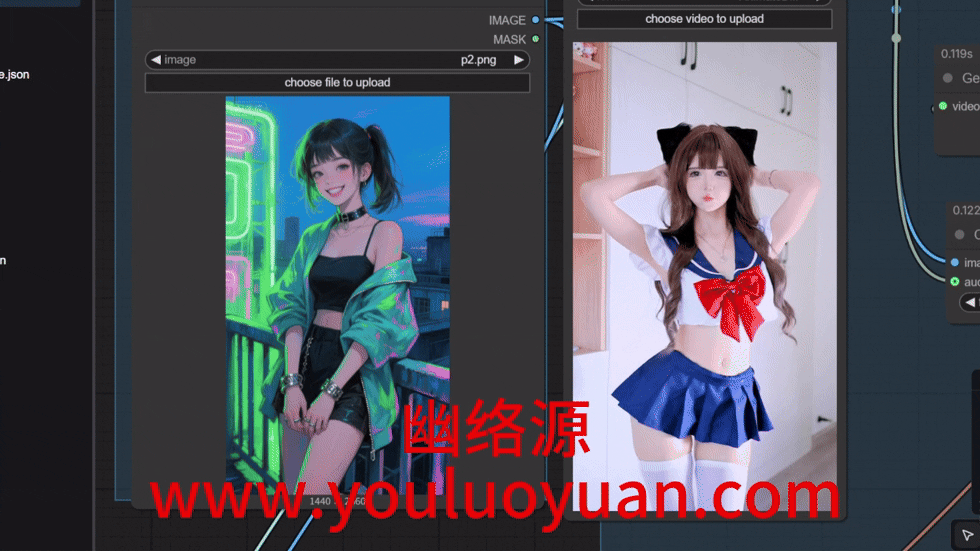
如下图是幽络源这里上传的图片和视频,用这个动漫人物替换掉视频中的真人。
点击执行后,结果如下
结语
以上为幽络源的“ComfyUI最强视频生成-通义万象图片替换视频人物生成新的视频”教程,如有疑问或对ComfyUI视频生成感兴趣可加入我们的QQ群307531422咨询交流学习

