概述
在互联网数据驱动的时代,掌握高效、稳定的数据采集能力已成为程序员进阶的必备技能。Python 作为爬虫开发的首选语言,其强大的生态和灵活的框架为开发者提供了广阔的空间。本次幽络源为大家精心整理并分享《mu课实战课-畅销3年的Python分布式爬虫课程》,这是一套经过市场验证、持续热销三年的高质量实战教学资源,内容系统全面、案例真实落地,适合从零基础到进阶提升的技术学习者。
本课程不仅涵盖主流爬虫技术栈的核心知识点,还深入讲解了反爬机制应对策略与分布式架构部署方法,帮助学习者构建完整的项目闭环思维。无论你是想从事数据分析、自动化运维,还是希望打造个人数据平台,这套课程都能为你提供坚实的技术支撑。
主要内容
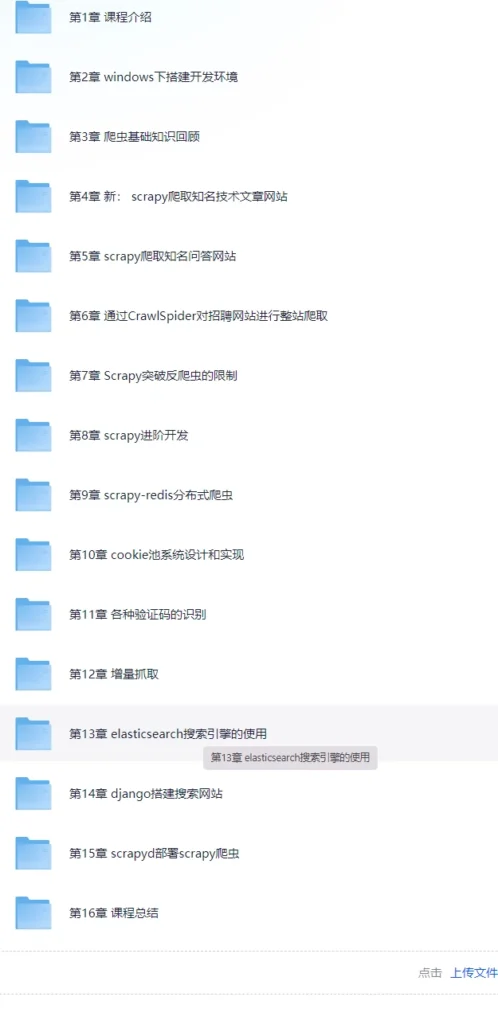
本课程共包含16个章节,结构清晰、循序渐进,覆盖从环境搭建到项目部署的完整流程,每一章都结合实际案例进行讲解,确保理论与实践深度融合。
第1章 课程介绍
简要说明课程目标、适用人群及整体学习路径规划。
第2章 Windows下搭建开发环境
详细演示PyCharm安装配置、MySQL与Navicat使用、Python 2/3环境部署以及虚拟环境搭建等基础准备工作,为后续开发打下坚实基础。
第3章 爬虫基础知识回顾
梳理HTTP协议、请求头、响应状态码等核心概念,巩固爬虫入门知识体系。
第4章 新:scrapy爬取知名技术文章网站
通过实际案例展示如何使用Scrapy框架抓取技术博客类站点内容,掌握Item定义与Pipeline处理流程。
第5章 scrapy爬取知名问答网站
进一步拓展应用场景,实现对问答社区(如知乎)的结构化数据提取。
第6章 通过CrawlSpider对招聘网站进行整站爬取
引入CrawlSpider机制,实现多层级页面的自动遍历与深度抓取,提升效率与完整性。
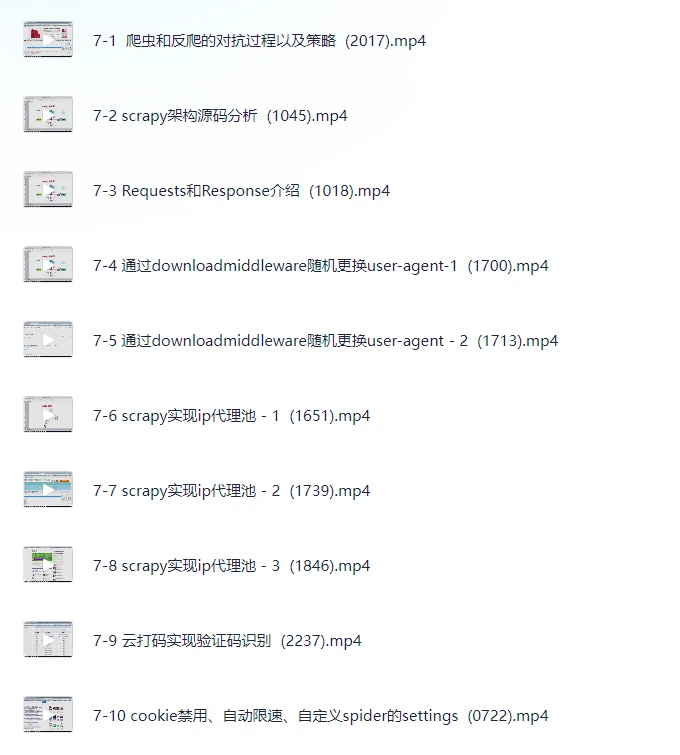
第7章 Scrapy突破反爬虫的限制
深入剖析反爬机制,包括User-Agent轮换、IP代理池构建、Cookie禁用与自动限速等高级技巧,并结合download middleware实现动态防护。
第8章 scrapy进阶开发
讲解自定义Spider、中间件扩展、信号机制等内容,提升代码复用性与可维护性。
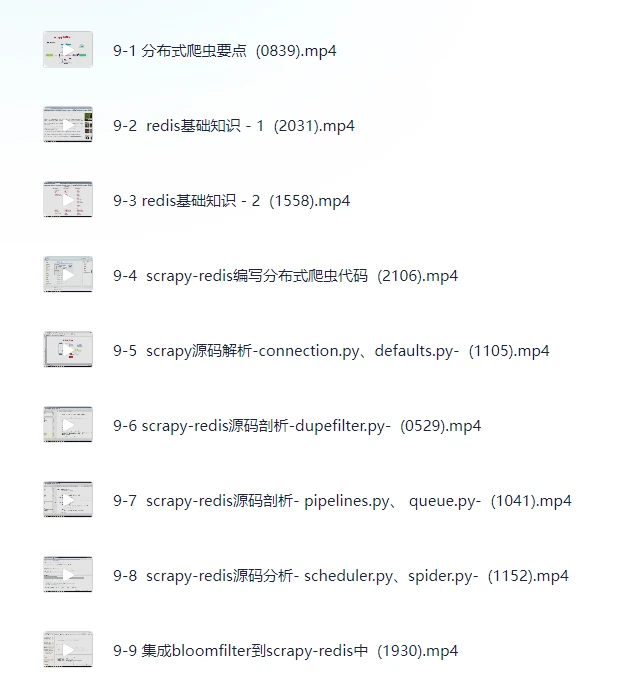
第9章 scrapy-redis分布式爬虫
系统讲解Redis在分布式架构中的作用,手把手教你怎么编写分布式爬虫代码,解析connection.py、dupefilter.py、scheduler.py等核心模块源码,集成bloom filter优化去重性能。
第10章 cookie池系统设计和实现
设计并实现一个可扩展的cookie池系统,用于绕过登录态验证,增强爬取稳定性。
第11章 各种验证码的识别
针对滑动验证码、图片验证码等常见类型,讲解识别思路与实现方案,包含截图、距离计算、轨迹模拟等关键技术点。
第12章 增量抓取
介绍如何基于时间戳或数据库记录实现增量更新,避免重复抓取,提高资源利用率。
第13章 elasticsearch搜索引擎的使用
讲解Elasticsearch的基本操作,包括索引创建、文档存储、查询语法等,为后续搜索功能做准备。
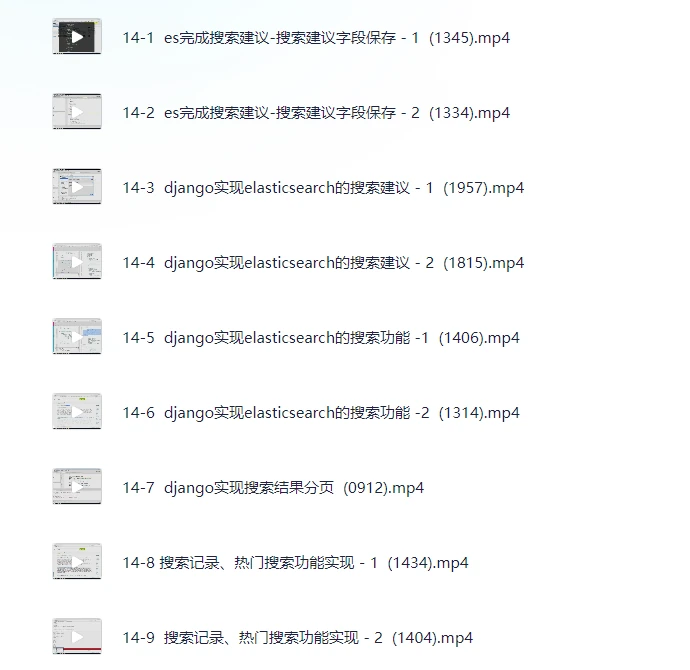
第14章 django搭建搜索网站
结合Django框架,实现基于Elasticsearch的搜索建议、搜索结果分页、热门搜索等功能,打造完整的前端交互体验。
第15章 scrapyd部署scrapy爬虫
演示如何使用scrapyd服务化部署爬虫任务,支持远程调度与集群管理,提升工程化水平。
第16章 课程总结
对整个课程内容进行回顾与升华,提炼关键技能点与学习方法论,帮助学员形成系统认知。
结语
这套《mu课实战课-畅销3年的Python分布式爬虫课程》不仅是技术学习的宝贵资料,更是一次从“能跑”到“能用”的实战跃迁。它融合了大量真实项目经验,涵盖了从基础环境配置到高并发分布式部署的全过程,非常适合想要系统掌握Python爬虫开发全流程的学习者。
如果需要其他相关编程资源,欢迎加入我们的QQ群 307531422 交流咨询,幽络源将为您提供更多优质的技术资源和服务。
转存观看
https://pan.quark.cn/s/20865db120e2
预览图