

直接上问题
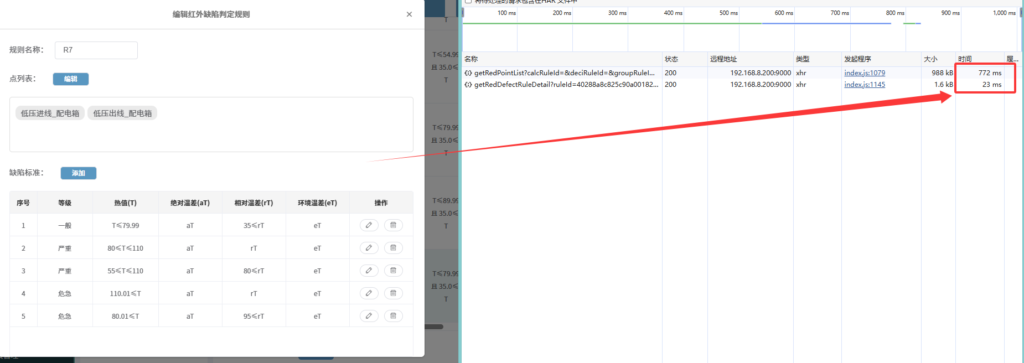
如下图为某公司某业务中的点击某一编辑按钮后弹出的对话框,仅仅是弹出该对话框,就需要人等待28秒。
且从下图可以看出这里调用了两个接口,第一个接口耗时27.85秒,第二个没什么问题,25毫秒,并且这两个接口是同步调用的,虽然第二个接口耗时25毫秒,但实际要等待第一个接口响应后才会开始调用。
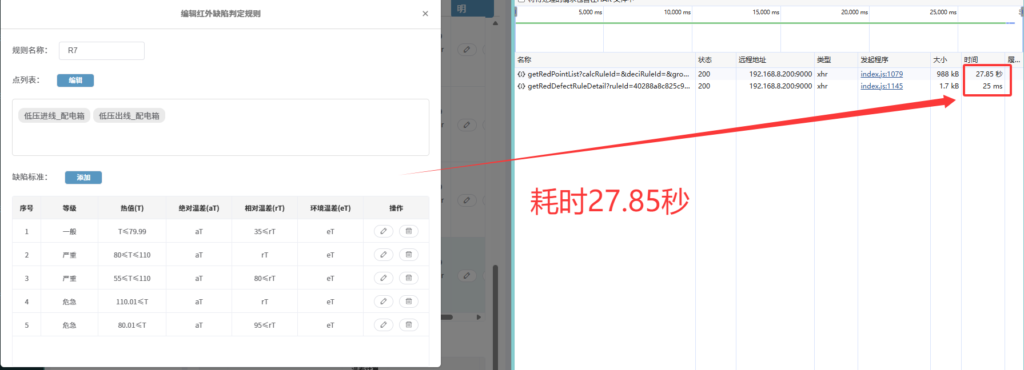
正文
1、找问题所在
幽络源寻思是数据量大了呢还是业务逻辑有问题呢?响应这么久?于是来到接口看看,如下图可以看到接口层仅调用了服务层
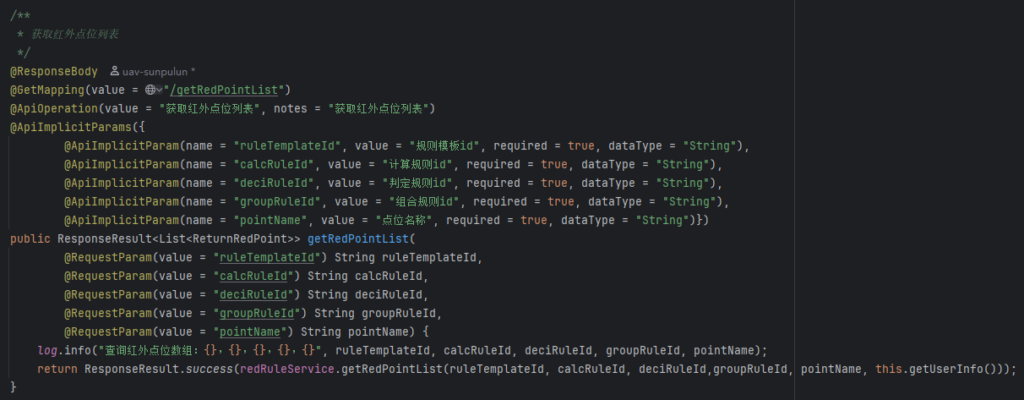
继续看服务层,如图服务层也仅仅是只做了sql查询,没有什么业务逻辑,然后又去看了看表的数据量也才不到2万,由此可以判断为SQL语句出问题了
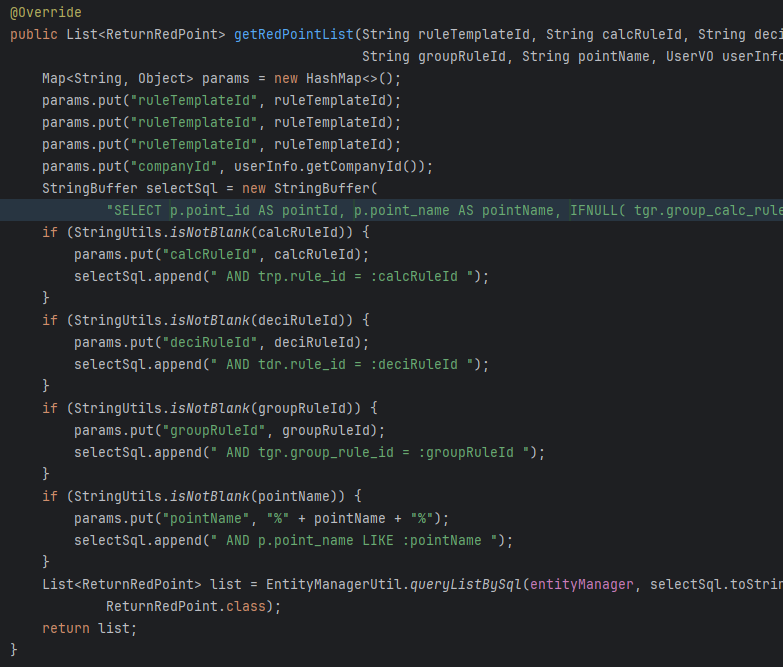
且上图的可以看出这里持久层还是用的JPA,SQL被写在了一行,这是一种非常不利于调试的SQL的框架,不利于观察的排版方式
2、预处理并复现问题
如下图,我这里首先整理了下SQL的排版,便于观察
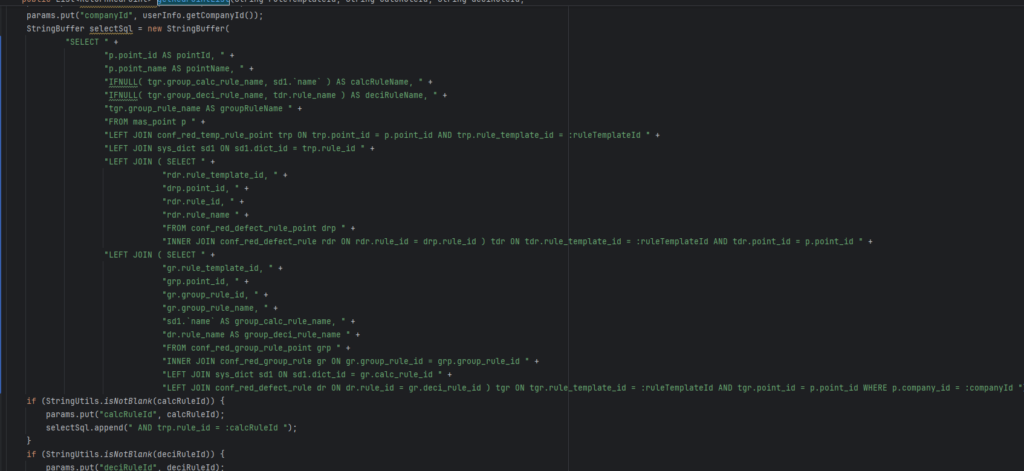
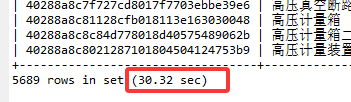
然后将SQL提取并带上最开始调用接口时传入的参数,在navicat中执行查询看看耗时,如图可以看到这条SQL耗时为30.32秒
执行sql图:

结果:
3、查原因
我们使用explain来分析这个SQL的性能,如图,执行后结果如下
执行explain:

结果:

从上图的结果可以看到这里p、trp、drp这三张表数据查询量最大,在type中 p表是已经有索引了的,但是trp和drp的查询type为all,也就是全表查
4、分析处理方式
由3原因可知,这里我们解决问题的切入点为trp表和drp表,当然,这里trp是表conf_red_temp_rule_point的别名,drp是表conf_red_defect_rule_point的别名,因此来给这两张表加索引。
索引如何加呢?这里还是得分析SQL的查询方法,对于conf_red_temp_rule_point表,连接的条件包含了其point_id和rule_template_id,对于conf_red_defect_rule_point表,连接条件包括了rule_id,然后这里还有个不明显的地方,那就是如下代码
LEFT JOIN (
SELECT
rdr.rule_template_id,
drp.point_id,
rdr.rule_id,
rdr.rule_name
FROM conf_red_defect_rule_point drp
INNER JOIN conf_red_defect_rule rdr ON rdr.rule_id = drp.rule_id
) tdr ON tdr.rule_template_id = "40288a8c8238149a0182389336750172" AND tdr.point_id = p.point_id上面这段代码中将子查询结果起别名为tdr,然后使用了其point_id,而子查询中的point_id就是conf_red_defect_rule_point表的point_id,因此我们建立索引的结果总结为如下:
1.在conf_red_temp_rule_point表创建复合索引,字段包括rule_template_id、point_id
2.在conf_red_defect_rule_point表创建复合索引,字段包括rule_id、point_id5、创建索引
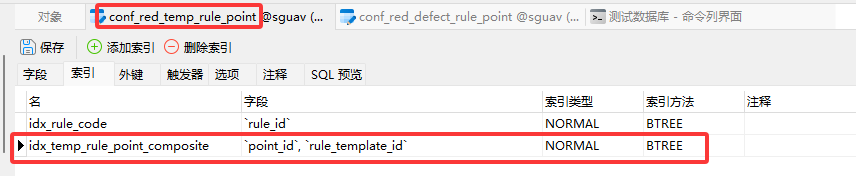
具体创建我这里使用navicat来操作,方便快捷,如图为conf_red_temp_rule_point创建的索引
如图为conf_red_defect_rule_point表创建的索引

6、测试效果
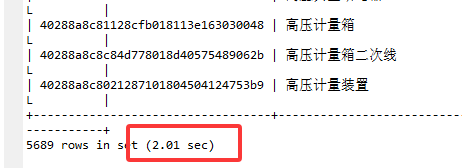
如图可以看到这次我们执行该SQL只用了2秒左右
再来看接口,如图可以看到接口的响应耗时由原来的28秒左右优化到了不到一秒钟
结语
以上是幽络源的【MySQL索引优化实战:28秒→1秒接口性能提升 | 全栈必看教程】,如对MySQL有更好的见解或疑问可以加入我们的QQ群学习交流307531422







暂无评论内容