

概述
在上篇教程 https://www.youluoyuan.com/4085.html,我们已经完成了yolov11的下载、配置、初步使用,上篇教程我们测试的模型是官方提供的yolo11n.pt,该模型包括了几十种类别识别,但如果我们要针对特定类别来做识别,就需要针对性的训练模型了。
正文
准备数据集
这里提供一份 电网绝缘子及破损、闪络缺陷YOLO数据集 ,下载后将其放置于 ultralitics目录并解压重命名,不要带有中文文字,我这里命名为dataset,如图

修改数据集配置文件
在数据集中有一个data.yaml文件,主要是用来指定训练集、验证集、测试集的路径以及类别名的,如图,我们需要修改训练集、验证集的路径,测试集可有可无,这里直接用 / 占位即可

准备中文字体
由于在yaml中我们配置的类别名为中文,若不配置中文字体,后续训练出来的结果图标则会是乱码
中文字体下载 => 文泉驿正黑字体
下载后,将字体文件解压随便放个位置,如图

开始训练
训练代码如下
from matplotlib import font_manager, pyplot as plt
from ultralytics import YOLO
fontPath="E:/X04Fonts/wqy-zenhei/wqy-zenhei.ttc" #字体路径
font = font_manager.FontProperties(fname=fontPath)
# 重新加载字体
font_manager.fontManager.ttflist = []
font_manager.fontManager.addfont(fontPath)
plt.rcParams['font.family'] = font.get_name()
# 加载YOLOv8模型(可以是预训练模型,也可以是新的模型)
model = YOLO("yolo11n.pt")
# 设置训练配置
train_config = {
'data': 'D:/ultralytics-main/dataset/data.yaml', # windows数据集路径
'epochs': 100, # 训练轮数
'batch': 8, # 批量大小
'imgsz': 640, # 输入图像尺寸
'workers': 16, #使用核心数
'device': '0', # 训练所使用的GPU设备,0表示第一块GPU
'project': 'runs/train', # 保存训练结果的文件夹
'name': 'trainResult', # 训练结果保存的文件夹名称
'save_period': 50, # 每1个epoch保存一次模型
'resume' : False #是否继续训练
}
# 开始训练
if __name__ == '__main__':
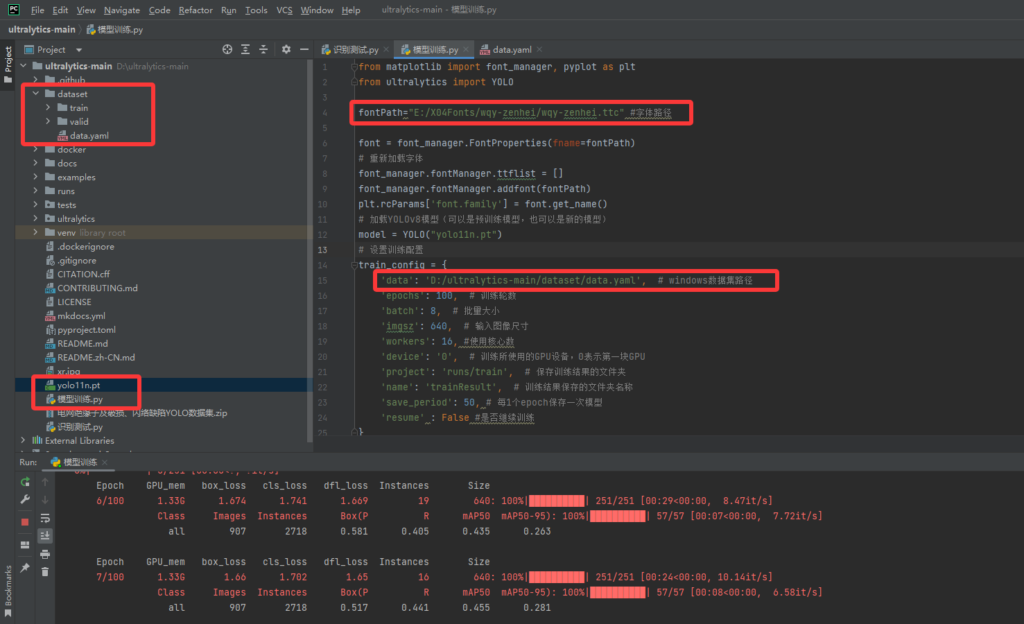
model.train(**train_config)根据自己的yaml文件位置、字体文件位置情况,修改配置,然后启动即可,如图
训练完成后的测试
在上面的训练代码中,我设置的轮次为100,如图可以看到用了1.053小时
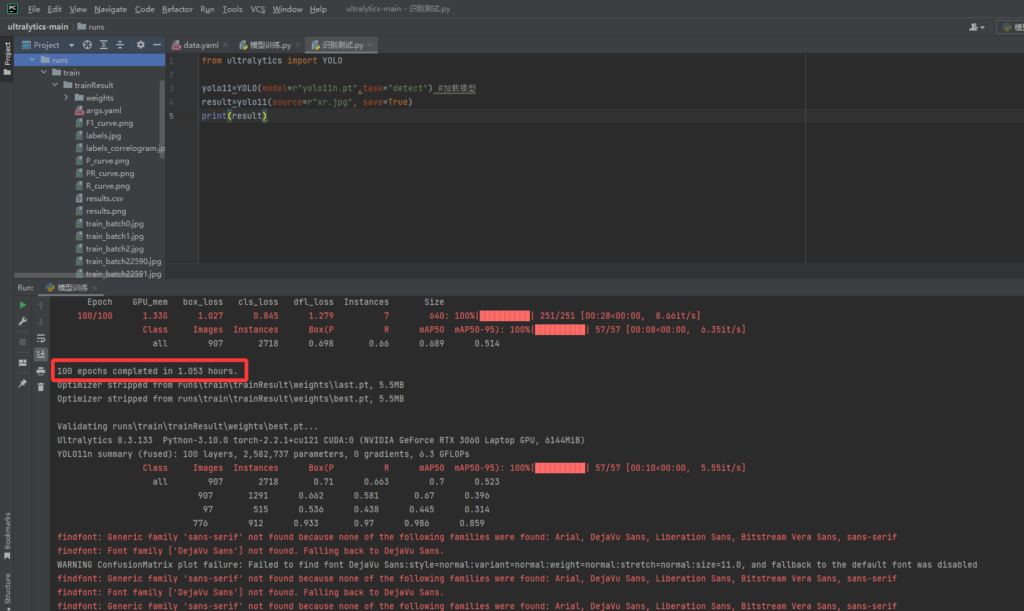
训练完成后,会自动在runs/train目录下生成训练的结果,其中包括了模型,如图best.pt表示是训练的最优模型

为了测试模型,我找了一些绝缘子破损的相关图片,放在了如下目录
D:\A01Python392Pros\爬取\绝缘子破损
然后使用如下代码进行识别输出,注意:source参数可以传一张图也可以传一个包含图片的目录
from ultralytics import YOLO
# 加载模型
yolo11 = YOLO(model=r"D:\ultralytics-main\runs\train\trainResult\weights\best.pt", task="detect")
# 运行检测并指定保存路径
result = yolo11.predict(
source=r"D:\A01Python392Pros\爬取\绝缘子破损",
save=True, # 保存检测结果
project="runs", # 主文件夹名称(默认是'runs')
name="detect", # 子文件夹名称(默认是'exp')
exist_ok=True # 允许覆盖已存在的文件夹
)
print(result)运行代码后会在runs/detect目录下得到识别后的图片,如图



结语
以上是幽络源的yolov11模型训练与中文字体配置教程,如有疑问或感兴趣的朋友可加QQ群307531422询问交流学习。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END





暂无评论内容